Доброго времени суток, уважаемые!
Одна из первых аксиом, которую вдалбливают в неокрепший ум будущего программиста - все ужеукрадено написано до нас. И чтобы усилить педагогический эффект этого внушения, более старшие товарищи обзывают неофита непонятным в данной ситуации термином "велосипедист", бубня на ухо, что мол "не надо изобретать велосипеды" и т.д. и т.п. и прррр.
А ведь иногда так хочется изобрести корявенький, кривой и косой, но свой велосипед. Холить его, лелеять его кривости и косости.
И втайне гордиться своим неказистым детищем))

Если вам не чуждо такое желание, если втайне вы всегда считали, что весь софт вокруг написан неправильно, но уж вы то точно сделаете лучше - то прошу следовать за мной, чтобы написать Лучшую На Свете Библиотеку Анализа XML (сокращенно - ЛНС-БАКС) и захватить мир!!!
 Сразу оговорюсь, в этой статье я не делаю ничего полезного с практической точки зрения, ничего прорывного, ничего революционного. Статья лишь иллюстрирует то, что написано тут, тут и тут в применении к задаче анализа XML.
Сразу оговорюсь, в этой статье я не делаю ничего полезного с практической точки зрения, ничего прорывного, ничего революционного. Статья лишь иллюстрирует то, что написано тут, тут и тут в применении к задаче анализа XML.
LL-синтаксический анализатор, соответствующий этой грамматике выглядит так:
Этот класс явно выражает тот факт, что у XML-документа должен быть только один корневой элемент. Также создадим класс Element, который будет представлять собой XML-тэг со всем его содержимым:
И класс Attribute, который представляет собой атрибут XML-тэга:
Этот XML-файл представляет просто pom-файл проекта на GitHub, содержащего исходный код данной статьи. Из этого файла я заблаговременно удалил пролог, чтобы не смущать анализатор непонятными символами в неожиданных местах). Выясним значение groupId, с помощью нашего анализатора. Написав простую программку
получим ожидаемый результат: com.blogspot.toolkas. Конечно этот мейничек не может быть заменой полноценному тестированию и все мы помним, что нужно-нужно-нужно писать модульные тесты.

Одна из первых аксиом, которую вдалбливают в неокрепший ум будущего программиста - все уже
А ведь иногда так хочется изобрести корявенький, кривой и косой, но свой велосипед. Холить его, лелеять его кривости и косости.
И втайне гордиться своим неказистым детищем))
Если вам не чуждо такое желание, если втайне вы всегда считали, что весь софт вокруг написан неправильно, но уж вы то точно сделаете лучше - то прошу следовать за мной, чтобы написать Лучшую На Свете Библиотеку Анализа XML (сокращенно - ЛНС-БАКС) и захватить мир!!!
План
Последовательность шагов проста и тривиальна:
- Создать лексический анализатор;
- Создать синтаксический анализатор;
- Создать модель XML документа;
Лексический анализатор
Лексический анализатор - это программа, которая разбивает последовательность входных символов на последовательность лексем (слов) определенных типов (токенов). По сути своей лексический анализатор представляет собой конечный автомат, который удобно представлять как набор состояний и переходов между ними под воздействием входных символов.
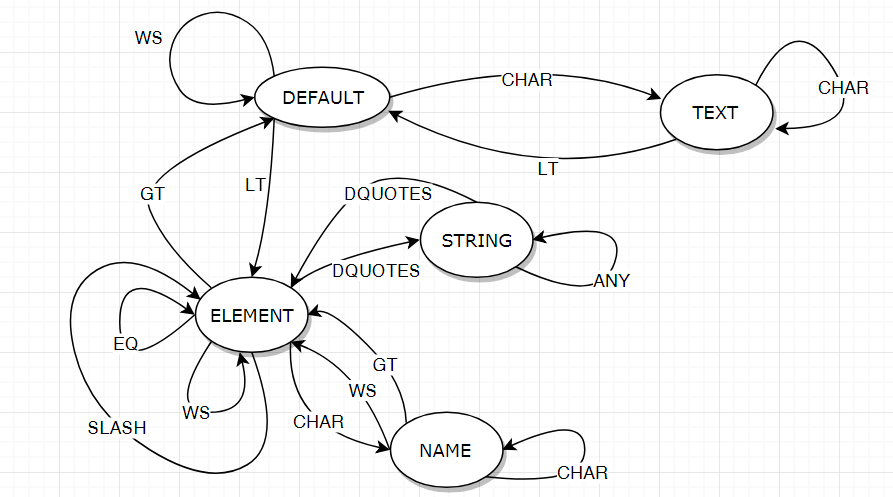
Для решения нашей задачи нарисуем диаграмму состояний конечного автомата нашего лексического анализатора. В первом приближении, это будет выглядеть как-то так:
На этой диаграмме кружками отмечены состояния конечного автомата. Стрелочками показаны переходы автомата между состояниями под воздействием входных символов.
Входные символы, согласно диаграмме, бывают такие:
- WS - whitespace - символы пробела, переноса строки и табуляции;
- GT - >;
- LT - <;
- EQ - =;
- DQUOTES - ";
- SLASH - /
- CHAR - любой символ английского алфавита, знак подчеркивания, дефис, двоеточие
- ANY - любой символ
Исходный код, соответствующий этому анализатору выглядит так (я немного вольно трактую диаграмму состояний, но суть сохранена):
package com.blogspot.toolkas.xml.lexer;
import java.util.ArrayList;
import java.util.List;
import java.util.Objects;
public class XmlLexer {
private TokenizeState state = TokenizeState.DEFAULT;
private String expression;
private String value = "";
private int position = -1;
public XmlLexer(String expression) {
Objects.requireNonNull(expression, "expression can't be null");
this.expression = expression;
}
public List tokenize() throws TokenizeException {
List lexems = new ArrayList<>();
int ch;
while ((ch = get()) != -1) {
Lexem lexem = nextLexem(ch);
if (lexem != null) {
lexems.add(lexem);
}
}
if (state != TokenizeState.DEFAULT) {
Lexem lexem = nextLexem(ch);
if (lexem != null) {
lexems.add(lexem);
}
}
if (value != null && value.trim().length() > 0) {
throw new TokenizeException("can't parse '" + value + "'");
}
lexems.add(new Lexem(Token.EOF, null));
return lexems;
}
private Lexem nextLexem(int b) throws TokenizeException {
char ch = (char) b;
switch (state) {
case DEFAULT:
if (ch == '<') {
state = TokenizeState.ELEMENT;
return new Lexem(Token.LT, "<");
} else if (Character.isWhitespace(ch)) {
return null;
} else {
state = TokenizeState.TEXT;
value += ch;
}
break;
case TEXT:
if (ch == '<') {
state = TokenizeState.DEFAULT;
position -= 1;
try {
return new Lexem(Token.TEXT, value);
} finally {
value = "";
}
}
value += ch;
break;
case ELEMENT:
if (ch == '"') {
state = TokenizeState.STRING;
} else if (ch == '=') {
return new Lexem(Token.EQ, "=");
} else if (ch == '/') {
return new Lexem(Token.SLASH, "/");
} else if (ch == '>') {
state = TokenizeState.DEFAULT;
return new Lexem(Token.GT, ">");
} else if (Character.isWhitespace(ch)) {
return null;
} else if (Character.isAlphabetic(ch)) {
state = TokenizeState.NAME;
value += ch;
}
break;
case STRING:
if (ch == '"') {
state = TokenizeState.ELEMENT;
try {
return new Lexem(Token.STRING, value);
} finally {
value = "";
}
}
value += ch;
break;
case NAME:
if (Character.isAlphabetic(ch) || Character.isDigit(ch) || ch == '_' || ch == '-' || ch == ':') {
value += ch;
} else {
state = TokenizeState.ELEMENT;
position -= 1;
try {
return new Lexem(Token.NAME, value);
} finally {
value = "";
}
}
}
return null;
}
private int get() {
position += 1;
return position < expression.length() ?
expression.charAt(position) : -1;
}
private enum TokenizeState {
DEFAULT, ELEMENT, NAME, STRING, TEXT;
}
}
Где класс Token, представляет собой токены языка:
package com.blogspot.toolkas.xml.lexer;
public enum Token {
LT, EQ, GT, SLASH, NAME, TEXT, STRING, EOF;
}
А класс Lexem - лексему языка
package com.blogspot.toolkas.xml.lexer;
public class Lexem {
private final Token token;
private final String value;
public Lexem(Token token, String value) {
this.token = token;
this.value = value;
}
public Token getToken() {
return token;
}
public String getValue() {
return value;
}
@Override
public String toString() {
return "Lexem{" +
"token=" + token +
", value='" + value + '\'' +
'}';
}
}
Синтаксический анализатор
Теперь напишем синтаксический анализатор. Для этого, как обычно, напишем грамматику языка XML. Она будет выглядеть так:
<xml> ::= <document>
<document> ::= <element>
<element> ::= "<" <NAME> <attribute>* ">" <content> "<" "/" NAME ">"
<element> ::= "<" <NAME> <attribute>* "/" ">"
<content> ::= <element>* | <TEXT>
<attribute> ::= <NAME> "=" <STRING>
LL-синтаксический анализатор, соответствующий этой грамматике выглядит так:
package com.blogspot.toolkas.xml.parser;
import com.blogspot.toolkas.xml.lexer.Lexem;
import com.blogspot.toolkas.xml.lexer.Token;
import com.blogspot.toolkas.xml.model.Attribute;
import com.blogspot.toolkas.xml.model.Document;
import com.blogspot.toolkas.xml.model.Element;
import java.util.List;
import java.util.Objects;
public class XmlParser {
private int position = 0;
public Document parse(List lexems) throws XmlParseException {
Element element = element(lexems);
return new Document(element);
}
private Element element(List lexems) throws XmlParseException {
consume(lexems, Token.LT);
Lexem name = consume(lexems, Token.NAME);
Element element = new Element(name.getValue());
while (check(lexems, Token.NAME)) {
Lexem lexem = prev(lexems);
consume(lexems, Token.EQ);
Lexem value = consume(lexems, Token.STRING);
Attribute attribute = new Attribute(lexem.getValue(), value.getValue());
element.add(attribute);
}
if (check(lexems, Token.SLASH)) {
consume(lexems, Token.GT);
} else {
consume(lexems, Token.GT);
if (check(lexems, Token.TEXT)) {
Lexem text = prev(lexems);
element.setText(text.getValue());
} else {
while (check(lexems, Token.LT)) {
if(check(lexems, Token.SLASH)) {
back();
back();
break;
}
back();
Element el = element(lexems);
element.addChild(el);
}
}
consume(lexems, Token.LT);
consume(lexems, Token.SLASH);
Lexem name2 = consume(lexems, Token.NAME);
consume(lexems, Token.GT);
if (!Objects.equals(name.getValue(), name2.getValue())) {
throw new XmlParseException("names are not equals");
}
}
return element;
}
private void back() {
position -= 1;
}
protected Lexem get(final List lexems, int offset) {
if (position + offset >= lexems.size()) {
return new Lexem(Token.EOF, null);
}
return lexems.get(position + offset);
}
protected boolean check(final List lexems, Token type) {
Lexem token = get(lexems, 0);
if (token.getToken() != type) {
return false;
}
position++;
return true;
}
protected Lexem consume(final List lexems, Token token) throws XmlParseException {
Lexem lexem = get(lexems, 0);
if (lexem.getToken() != token) {
throw new XmlParseException("expected {" + token + "}, but consumed {" + lexem.getToken() + "}");
}
return lexems.get(position++);
}
private Lexem prev(List lexems) {
return lexems.get(position - 1);
}
}
Наблюдательный читатель заметит, что эта грамматика описывает "не совсем" XML. Например нет пролога, инструкций обработки, комментариев. Но мне главное - продемонстрировать принцип велосипедостроительства, а того, что не хватает - читатель может легко дописать и сам))
Модель XML-документа
Результатом работы нашего анализатора должен быть объект, который хранит в себе всю структуру XML-файла. Для этого создадим класс Document, который хранит в себе весь документ:
package com.blogspot.toolkas.xml.model;
public class Document {
private final Element element;
public Document(Element element) {
this.element = element;
}
public Element getElement() {
return element;
}
}
Этот класс явно выражает тот факт, что у XML-документа должен быть только один корневой элемент. Также создадим класс Element, который будет представлять собой XML-тэг со всем его содержимым:
package com.blogspot.toolkas.xml.model;
import java.util.ArrayList;
import java.util.List;
public class Element {
private final String name;
private final List attributes = new ArrayList<>();
private String text;
private final List children = new ArrayList<>();
public Element(String name) {
this.name = name;
}
public String getText() {
return text;
}
public void setText(String text) {
this.text = text;
}
public String getName() {
return name;
}
public List getAttributes() {
return attributes;
}
public void add(Attribute attribute) {
attributes.add(attribute);
}
public void addChild(Element element) {
children.add(element);
}
public List getChildren() {
return children;
}
} И класс Attribute, который представляет собой атрибут XML-тэга:
package com.blogspot.toolkas.xml.model;
public class Attribute {
private final String name;
private final String value;
public Attribute(String name, String value) {
this.name = name;
this.value = value;
}
public String getName() {
return name;
}
public String getValue() {
return value;
}
@Override
public String toString() {
return "Attribute{" +
"name='" + name + '\'' +
", value='" + value + '\'' +
'}';
}
}
Пример
Теперь попробуем проанализировать следующий XML-файл:
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.blogspot.toolkas</groupId>
<artifactId>xml</artifactId>
<version>1.0-SNAPSHOT</version>
<name>xml</name>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
</plugins>
</build>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
</dependencies>
</project>
Этот XML-файл представляет просто pom-файл проекта на GitHub, содержащего исходный код данной статьи. Из этого файла я заблаговременно удалил пролог, чтобы не смущать анализатор непонятными символами в неожиданных местах). Выясним значение groupId, с помощью нашего анализатора. Написав простую программку
package com.blogspot.toolkas.xml;
import com.blogspot.toolkas.xml.lexer.Lexem;
import com.blogspot.toolkas.xml.lexer.TokenizeException;
import com.blogspot.toolkas.xml.lexer.XmlLexer;
import com.blogspot.toolkas.xml.model.Document;
import com.blogspot.toolkas.xml.model.Element;
import com.blogspot.toolkas.xml.parser.XmlParseException;
import com.blogspot.toolkas.xml.parser.XmlParser;
import org.apache.commons.io.IOUtils;
import java.io.ByteArrayOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.util.List;
public class Example {
public static void main(String[] args) throws IOException, TokenizeException, XmlParseException {
try(InputStream input = Example.class.getResourceAsStream("example.xml")) {
ByteArrayOutputStream output = new ByteArrayOutputStream();
IOUtils.copy(input, output);
String xml = output.toString("UTF-8");
XmlLexer lexer = new XmlLexer(xml);
List lexems = lexer.tokenize();
XmlParser parser = new XmlParser();
Document document = parser.parse(lexems);
Element project = document.getElement();
project.getChildren().stream()
.filter(element -> "groupId".equals(element.getName())).findAny()
.ifPresent(
element -> System.out.println(element.getText())
);
}
}
} получим ожидаемый результат: com.blogspot.toolkas. Конечно этот мейничек не может быть заменой полноценному тестированию и все мы помним, что нужно-нужно-нужно писать модульные тесты.
Итог
Итак, друзья, мой велосипедный проект завершен. Исходный код выложен на GitHub. Изучайте, берите за основу и пишите свои XML-анализаторы, лучше и быстрее существующих. И вообще, хочу по секрету сказать: занятия велосипедным спортом очень благотворно влияют на здоровье! До новых встреч!))
Комментариев нет:
Отправить комментарий